Le plus gros défi avec les LLMs, c’est qu’ils sont fondamentalement “stateless”. Sans une couche de gestion de session et de mémoire, chaque requête est une page blanche. Pour un développeur, la difficulté est de savoir quoi stocker, où le stocker et combien de temps le garder.
Pour transformer un simple chatbot en un agent intelligent, il faut mettre en place une architecture de contexte. Agent Development Kit (ADK) de Google répond à ce besoin en structurant la persistance autour de trois piliers : la Session, le State et la Memory.
En maîtrisant ces concepts, vous permettez à votre agent d’apprendre de ses interactions et de devenir plus pertinent au fil du temps, tout en gérant intelligemment la fenêtre de contexte limitée des modèles.
🏗️ Architecture du contexte dans ADK
🚦 Session, State et Memory
Il est crucial de différencier ces trois piliers pour ne pas surcharger la mémoire de travail de l’agent :
- « Session » : Le conteneur de la discussion actuelle (le « thread »). Elle contient la liste chronologique des événements.
- « State » : Le « bloc-notes » temporaire. On y stocke des données de travail (ex: un panier d’achat) qui disparaissent ou s’archivent à la fin de la discussion.
- « Memory » : La bibliothèque d’archives inter-sessions. Elle est consultable via une recherche sémantique pour ramener du contexte passé dans le présent.
🧠 Mémoire court-terme vs long-terme
Pour concevoir un agent performant, il faut séparer les flux comme le fait le cerveau humain :
- Short-Term Memory (Sessions & State) : Mémoire de travail active uniquement durant la conversation en cours . Elle sert à suivre la progression ou stocker des calculs intermédiaires. Une fois la session fermée, cette mémoire disparaît (ou est envoyée vers l’archivage).
- Long-Term Memory (Memory Bank) : Elle ne contient pas le texte brut, mais des faits consolidés (ex: « L’utilisateur préfère Python »). L’agent consulte cette archive au début de chaque nouvelle session pour ne pas repartir de zéro.
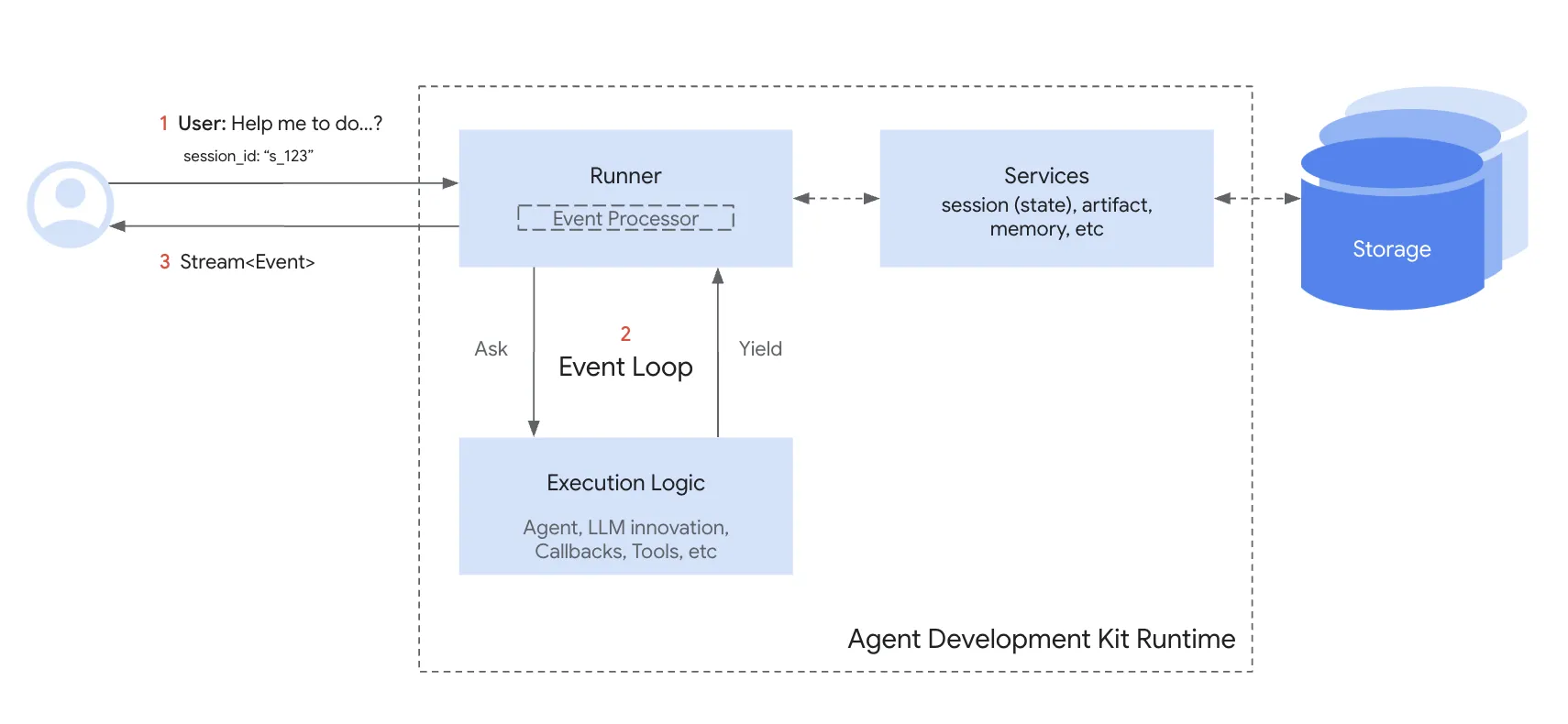
🔄 SessionService : Garantir la continuité
L’objet Session est le composant fondamental du suivi. Sans lui, chaque interaction repartirait de zéro.
Une session se définit par plusieurs propriétés clés :
- Identification : Elle lie un identifiant unique (
id), un nom d’application (app_name) et un identifiant utilisateur (userId). - Historique (
events) : Une séquence chronologique de tous les objets Event (messages utilisateur, réponses de l’agent, appels d’outils) survenue dans ce thread. - État (
state) : Un dictionnaire de données temporaires servant de « bloc-notes » à l’agent durant l’interaction. - Suivi d’activité (
lastUpdateTime) : Un horodatage indiquant la dernière interaction dans la session.
Le choix du service dépend de votre besoin de persistance et de contrôle :
| Service | Persistance | Usage recommandé |
|---|---|---|
| InMemorySessionService | Nulle | Développement local et tests unitaires. |
| VertexAiSessionService | Élevée | Production managée sur Google Cloud. |
| DatabaseSessionService | Élevée | Contrôle total sur votre propre base (PostgreSQL, SQLite). |
💡 Le Rewind : Annuler et corriger
Le Rewind permet de faire revenir une session à un état précédent via un
invocation_id. Cela restaure le State tel qu’il était avant une erreur de l’agent, permettant de repartir sur une base saine sans perdre tout l’historique.
📝 State : Le bloc-notes dynamique de l’agent
Dans ADK, l’attribut state d’une session est un dictionnaire clé-valeur servant de mémoire de travail. Contrairement à l’historique complet des événements, il stocke des détails structurés nécessaires au tour de conversation actuel (ex: statut d’authentification, étape d’un formulaire).
💡 Gestion de la portée via les préfixes
ADK utilise des préfixes pour définir automatiquement la visibilité et la durée de vie des données:
| Préfixe | Portée (Scope) | Persistance | Cas d’usage |
|---|---|---|---|
| Aucun | Session actuelle | Liée au service de session | Étape d’un tunnel d’achat. |
| user: | Identité utilisateur | Partagée entre toutes ses sessions | Préférences, nom. |
| app: | Application globale | Partagée entre tous les utilisateurs | Version API, code promo. |
| temp: | Invocation en cours | Éphémère (effacée après la réponse) | Calculs intermédiaires. |
Exemple d’utilisation
# The ADK automatically replaces {user:name} with the value found in state
agent = adk.LlmAgent(
instruction="Greet the user by saying: Hello {user:name}!"
)
# Updating state within a tool safely
@adk.tool
async def set_preference(color: str, context: adk.ToolContext):
context.state["user:fav_color"] = color # Captured and persisted automatically
return f"Preference saved."🧠 MemoryService : Choisir son moteur de connaissances
Dans ADK, le MemoryService est l’interface qui gère l’archivage et la récupération des connaissances à long terme. Sa mission est double : ingérer les informations pertinentes d’une session terminée (add_session_to_memory) et permettre à l’agent de les retrouver via une recherche (search_memory).
Il existe deux implémentations principales selon vos besoins en persistance et en intelligence :
| Caractéristique | InMemoryMemoryService | VertexAiMemoryBankService |
|---|---|---|
| Persistance | Nulle (perdue au redémarrage) | Élevée (Managée par Vertex AI) |
| Extraction | Stocke l’historique brut | Intelligente (extraite et consolidée par LLM) |
| Type de recherche | Mots-clés basiques | Sémantique avancée (Embeddings) |
| Usage idéal | Prototypage et tests rapides | Production et apprentissage continu |
🚀 Le workflow complet
Pour bien comprendre comment ces composants interagissent, voici le cycle de vie d’une information, de sa captation à sa réutilisation:
- Interaction : L’utilisateur échange avec l’agent via une Session. Chaque message et action est enregistré comme un Event, et le State gère les données de travail immédiates.
- Archivage : Lorsqu’une session est jugée riche en informations, l’application appelle
add_session_to_memory(session). Le système extrait les faits marquants de l’historique et les consolide dans leMemoryService. - Mémoire : Dans une session future, l’agent utilise un outil dédié (
LoadMemoryToolouPreloadMemoryTool) s’il détecte un besoin de contexte passé. - Recherche Sémantique : L’outil interroge le service de mémoire (
search_memory). S’il s’agit de la Memory Bank, une recherche par similarité vectorielle est effectuée pour trouver les souvenirs les plus proches du sens de la requête. - Restitution & Réponse : Le service renvoie les souvenirs pertinents (
MemoryResult). L’agent les intègre alors dans ses instructions système pour formuler une réponse personnalisée et historiquement cohérente.
🤖 Vers une IA qui apprend vraiment
En maîtrisant ce trio, Session, State et Memory, vous sortez enfin du mode “stateless” des LLM. Cette architecture, propulsée par ADK et Google Cloud, garantit que vos agents ne se contentent pas de répondre, mais s’adaptent et valorisent chaque interaction sur le long terme.